Pipeline di ingestione dei dati
Pipeline di ingestione
ZADIG XDR offre un'efficiente pipeline di ingestione dei dati che automatizza il processo di collezionamento degli stessi, assicurando che i dati provenienti dalle varie sorgenti siano integrati, elaborati e poi archiaviati in modo coerente ai requisiti definiti.
La nostra soluzione XDR è totalmente flessibile e abilita l’integrazione di dati provenienti da innumerevoli tipologie di sorgenti (ad esempio log provenienti da altri ambienti/produttori). Infatti, il componente che si occupa della gestione della pipeline di ingestione è in grado di collezionare dati provenienti da sorgenti diversificate attraverso plugin di input quali syslog o TCP. Si specifica che il collezionamento di dati da nuova sorgente può essere configurato in qualunque momento, anche a seguito dell'effettiva messa in opera della piattaforma XDR, al fine di accomodare eventuali modifiche dell’infrastruttura dell’organizzazione monitorata.
Le principali metodologie di ingestione di log supportate sono:
- SYSLOG Collector
- CSV Collector
- DB Collector
- FTP Collector
- NetFlow Collector
- Windows Event Collector
- Kafka Collector
- HTTP
- raccolta di log utilizzando filebeat
La soluzione integra nativamente kafka come tecnologia di log collection, ad esempio per l’ingestione dei dati monitorati dal suo modulo IDPS integrato (quando previsto), la metodologia di collection basata su protocollo SYSLOG per l’integrazione dei log derivanti da altri dispositivi o apparati presenti nell’infrastruttura, e la metodologia di collection basata sulla lettura di file per l’integrazione dei log derivanti da altri componenti che producono un feed di alert testuale su file. È chiaro che tutte le altre metodologie di collection possono essere facilmente attivate in base alle specifiche esigenze.
Di seguito un esempio di file di configurazione di Logstash che abilita l’integrazione dei log provenienti da un firewall di rete con installato sistema operativo pfSense:
input {
tcp {
id => "pfSense-suricata"
port => 5544
type => "suricata"
codec => line
mode => "server"
ssl_enable => true
ssl_certificate_authorities => ["/usr/share/logstash/config/bundle-ca-pfSense.crt"]
ssl_cert => "/usr/share/logstash/config/logger.smart.zadig.cloud_cert.pem.cer"
ssl_key => "/usr/share/logstash/config/key-server.key"
}
syslog {
port => 5514
type => "firewall-1"
id => "pfSense-AzSentinel-1"
}
}
In aggiunta, la nostra soluzione XDR offre un supporto nativo per l'integrazione con Azure AD. Affinché sia possibile raccogliere in modo efficiente i log da Azure Active Directory (AD), è necessario configurare Azure Monitor per esportare i log su Event Hub. Il sistema presenta una pipeline già ottimizzata per la raccolta dei dati provenienti da Event Hub.
Al fine di integrare i log provenienti da Microsoft AD, è richiesta l'attivazione di un servizio di Windows sul server domain controller on-premises. A questo software è demandata la raccolta e l'invio dei log al componente di ingestione.
In termini più generali, nel caso in cui una qualsiasi altra soluzione di Identity non supportasse un'integrazione diretta dei log con la nostra soluzione XDR e qualora tale soluzione integrasse i dati in un Security Information and Event Management (SIEM), sarebbe possibile collezionare questi ultimi configurando il SIEM come ennesima sorgente dati diretta della piattaforma XDR.
Repository dei dati
La soluzione XDR è predisposta per interagire con repository di dati situati on-premises o in cloud. In particolare, i repository di dati in cloud nativamente integrati nella soluzione sono Opensearch di AWS e Log Analytics di Microsoft Azure ed on-premises Elasticsearch. I repository supportano un motore di ricerca distribuito, con un’interfaccia web HTTP e documenti in formato JSON. Il componente di gestione della pipeline dei dati dovrà interagire con il già menzionato repository per il salvataggio di quanto inviato da ciascuna sorgente sfruttando un apposito plugin di output. Le uniche informazioni necessarie al plugin per salvare correttamente i dati all’interno del repository sono l’indirizzo o nome DNS del repository e l’indice/tabella contenitore dei dati stessi.
Di seguito un estratto di file di configurazione per salvare i dati su un cluster di Opensearch su AWS:
opensearch {
hosts => ["https://vpc-aws8672558-oss-ec1-zadig-01-k2qdi2aw6wtmijc5phkvpblzoe.eu-central-1.es.amazonaws.com:443"]
auth_type => {
type => 'aws_iam'
region => 'eu-central-1'
}
index => "logstash-%{+YYYY.MM}"
action => "create"
ssl => true
ecs_compatibility => disabled
#ilm_enabled => false
}
Di seguito un estratto di file di configurazione per salvare i dati su Log Analytics:
microsoft-sentinel-logstash-output-plugin {
client_app_Id => "cd4d90a2-287c-497d-81d9-fb334ee836d4"
client_app_secret => "t6r8Q~EDcw6NidiKB.vaWpxcNQZtmMN4H2dMcdlm"
tenant_id => "8b344519-45d1-44ff-a276-5a67ae3890ce"
data_collection_endpoint => "https://logs-ingestion-1ogm.westeurope-1.ingest.monitor.azure.com"
dcr_immutable_id => "dcr-0a9941bcd9244ba3a4a15a6bf491b01a"
dcr_stream_name => "Custom-gatewaylogs_CL"
#create_sample_file => true
#sample_file_path => "/tmp"
}
Quando il repository è in cloud, tramite un adapter di log collection, distribuito anch'esso direttamente in cloud risulta possibile integrare sorgenti dati, supportando diversi protocolli, quali Syslog (CEF, LEEF, CISCO, CORELIGHT o RAW - UDP, TCP o Secure TCP, consentendo di impostare una versione minima di TLS 1.2), CSV, Database (MySQL, PostgreSQL, MSSQL o Oracle), Cloud (AWS, Azure, Google), File e cartelle, FTP, NetFlow e Windows Events.
On-premises sono predisposti, per ovvie ragioni, eventuali aggregatori di log che si limitano a raccogliere i dati dalle fonti presenti sulla sede, applicare logiche di parsing totalmente personalizzabili sui dati stessi ed inviare il risultato in cloud. Tutto questo avviene real-time senza che nessuna informazione venga anche momentaneamente mantenuta localmente.
Gli aggregatori di log presenti on premise supportano il deploy affidabilità e sono compatibili con i seguenti hypervisor sia cloud che private:
• Amazon Web Services (AWS)
• Microsoft Azure
• Microsoft Hyper-V
• VMware ESXi
Risulta possibile effettuare il deploy degli aggregatori di log su macchina virtuale (VM) o su container.
Di seguito un esempio di deploy dell’aggregatore di log su macchina virtuale attiva su Amazon Web Services (AWS):

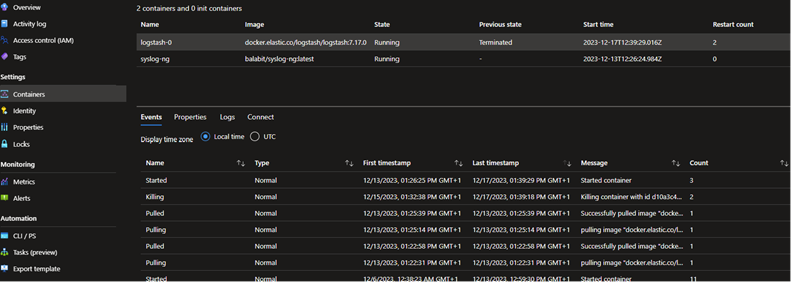
Di seguito un esempio di deploy degli aggregatori di log su container su Microsoft Azure:
Policy di retention dei dati
ZADIG XDR conserva nativamente i dati su Elasticsearch o altro storage cloud equivalente. Il sistema consente la creazione di una lifecycle policy sui dati tale da attivare una certa policy di retention sugli stessi, completamente personalizzabile in base alle esigenze della specifica organizzazione destinataria della soluzione.
I dati sono conservati all'interno del repository divisi per indici, su ogni indice è possibile impostare una policy di retention specifica.
Ad esempio, i dati generici (non afferenti ad incidenti informatici) sono conservati in indici del database creati ad-hoc, suddivisi eventualmente per categorie, su cui risulta possibile applicare una policy di retention a scelta (ad esempio almeno 30 giorni). Dati di altra natura, ad esempio quelli relativi agli incidenti di cybersecurity, sono conservati invece in indici differenti, ai quali si può applicare una retention maggiore (ad esmepio almeno 180 giorni).
Al fine di conservare i dati (anche solo alcune specifiche tipologie di questi) per un tempo illimitato, occorre impostare la policy di retention di conseguenza.
La nostra soluzione XDR consente la suddivisione della retention dei dati in hot e cold e considerando alcune tipologie di repository abilita l’aggiunta dello stato di retention warm.
La categorizzazione viene gestita come segue:
• Hot: l’indice è in continuo aggiornamento e viene spesso interrogato;
• Warm: l’indice non viene più aggiornato ma viene ancora interrogato;
• Cold: l’indice non viene né aggiornato né interrogato.
L'espansione dello spazio di storage se e quando necessario viene effettuata in modo trasparente senza generare interruzioni del servizio.
Confidenzialità dei dati e delle comunicazioni
I dati mantenuti nel repository in cloud sono gestiti nel pieno rispetto della privacy. Essi sono conservati nello spazio cloud dell’organizzazione oggetto del monitoraggio e sono cifrati sia in transito che “at rest” con algoritmi di encryption sofisticati, quali almeno AES-256. L’accesso agli stessi è gestito in maniera granulare e garantito solo all’entità che necessitano dell’accesso per ragioni di funzionalità dell’intera soluzione.
Le comunicazioni tra i vari componenti della soluzione sono completamente cifrate con protocollo TLS. La versione minima di protocollo TLS utilizzabile per la cifratura dei dati in transito è TLS v1.2. Ciascun plugin di input è predisposto per accettare comunicazioni cifrate, nel caso il plugin non dovesse supportare TLS, è predisposto apposito proxy TLS per la ricezione sicura dei dati all’esterno. Allo stesso modo, la nostra soluzione XDR trasmette i dati al repository utilizzando protocollo TLS.
Si specifica che ciascun componente integrato nella nostra soluzione XDR offre API per l’automazione.