Parsificazione ed interrogazione dei dati
La nostra soluzione XDR include procedure standard e un linguaggio specifico per l'esecuzione di query volte all'analisi delle informazioni disponibili.
Le varie informazioni possono essere organizzate in dashboard, ognuna delle quali contiene diversi pannelli di visualizzazione.
Per creare un nuovo pannello, basta accedere a una dashboard e cliccare su "Add a new panel":
La schermata per la creazione di un pannello consente di impostare una query di ricerca da eseguire su una specifica data source, ovvero su uno specifico indice o tabella presente nel repository dei dati. Ad ogni pannello deve essere associata una visualizzazione attraverso cui mostrare i dati.
Di seguito è riportata la schermata per la creazione di un pannello:
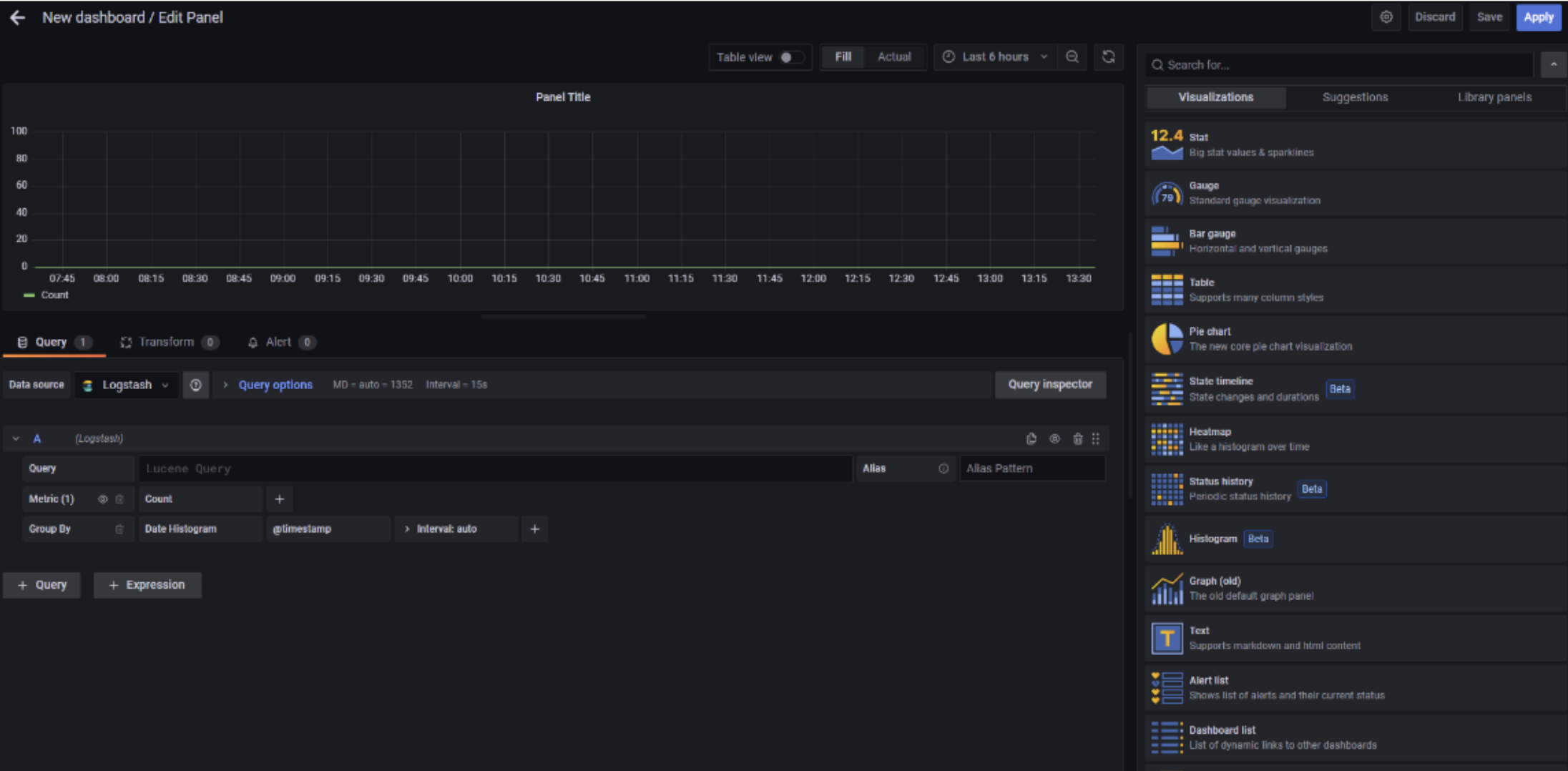
Il linguaggio di query offerto dalla nostra soluzione supporta, tra le altre cose, le seguenti funzionalità: filtraggio per individuare condizioni specifiche, la scelta di un sottoinsieme di campi da mostrare, la trasformazione di determinati campi restituiti dalla query, il calcolo di media, conteggio ecc, la possibilità di ordinare i risultati e la gestione dei deduplicati. Esiste un set di query predefinito. Ogni query può essere associata ad una dashboard per attivarne il continuo monitoraggio o per eseguirla on-demand su dati afferenti ad uno specifico intervallo di tempo.
Ciascuna query può essere trasformata in un BIOC, associando alla stessa un alert. Questo consentirà di monitorare ed individuare nuovi eventi sospetti oppure ricercare quel BIOC su dati esistenti che lo attivano.
Parsing dei dati
È disponibile una piattaforma specifica per la gestione dei file contenenti la configurazione delle regole di parsing, di fatto dei filtri che vengono applicati ai dati grezzi ingeriti in ingresso dal componente di ingestione dei dati. Tal\i filtri consentono l’eliminazione di un dato potenzialmente inutile, con l’obiettivo di ridurre i costi di archiviazione. Inoltre, consentono l’arricchimento dei dati con tag utilizzabili dal resto del flusso di raccolta, ad esempio di seguito un estratto della configurazione che aggiunge dei tag se determinate condizioni sono soddisfatte:
if [process][name] =~ /^dhcpd$/ {
mutate {
add_tag => [ "dhcp", "dhcpdv4", "firewall" ]
add_field => { "[event][dataset]" => "pfAzSentinel.dhcp" }
}
grok {
patterns_dir => [ "/usr/share/logstash/patterns" ]
match => [ "filter_message", "%{DHCPD}"]
}
}
I filtri di parsing consentono inoltre l’aggiunta di informazioni efficaci per il rilevamento di minacce, come quella relativa alla geolocalizzazione di un indirizzo IP, di seguito il frammento di configurazione creato per adempiere il già menzionato scopo:
if [destination][ip] {
### Check if destination.ip address is private
cidr {
address => [ "%{[destination][ip]}" ]
network => [ "0.0.0.0/32", "10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16", "fc00::/7", "127.0.0.0/8", "::1/128", "169.254.0.0/16", "fe80::/10", "224.0.0.0/4", "ff00::/8", "255.255.255.255/32", "::" ]
add_tag => "IP_Private_Destination"
}
if "IP_Private_Destination" not in [tags] {
geoip {
source => "[destination][ip]"
#MMR# database => "/var/lib/GeoIP/GeoLite2-City.mmdb"
target => "[destination][geo]"
}
geoip {
default_database_type => 'ASN'
#MMR# database => "/var/lib/GeoIP/GeoLite2-ASN.mmdb"
source => "[destination][ip]"
target => "[destination][as]"
}
mutate {
rename => { "[destination][as][asn]" => "[destination][as][number]"}
rename => { "[destination][as][as_org]" => "[destination][as][organization][name]"}
rename => { "[destination][geo][country_code2]" => "[destination][geo][country_iso_code]"}
rename => { "[destination][geo][region_code]" => "[destination][geo][region_iso_code]"}
add_tag => "GeoIP_Destination"
}
}
}